
I am Lijian Lin, a Computer Vision Researcher at International Digital Economy Academy (IDEA) . Previously, I was a Computer Vision Researcher at Tencent ARC Lab.
. Previously, I was a Computer Vision Researcher at Tencent ARC Lab.
My current research focuses on talking head generation, human video synthesis, talking body generation, human-centric 3D Gaussian Splatting, and video content generation. I welcome opportunities for academic collaboration — please feel free to contact me at linlijian@idea.edu.cn. I got my BS degree from Xiamen University in 2021, advised by Prof. Hanzi Wan.
I serve as a reviewer for international conferences, e.g., CVPR, ICCV, ECCV, NeuIPS, ICLR, ICML, ACM MM, AAAI, etc..
👏 We are currently looking for self-motivated interns to explore cutting-edge techniques such as Gaussian Splatting and DM/FM. Feel free to contact me if you are interested. zhihu
🔥 News
- [July, 2025]: 🎉 One TVCG paper is accepted. Project and demos are coming soon.
- [June, 2025]: 🎉 Two ICCV papers are accepted. Codes and demos are coming soon.
- [May, 2025]: 🎉 We introcuce GUAVA, a new Upper Body 3D Gaussian Avatar.
- [May, 2025]: 🎉 The code of
HRAvatarhas been released. - [March, 2025]: 🎉 The code of
TEASERhas been released. - [February, 2025]: 🎉 Our
HRAvatarhas been accepted to CVPR 2025. -
[Jan, 2025]: 🎉 Our
TEASERhas been accepted to ICLR 2025. - [2024]: 5 papers have been accepted by ICLR, CVPR, AAAI, ECCV.
Click for More
- [December, 2024]: 🎉 One <a href=https://aaai.org/Conferences/AAAI-25/>AAAI</a> paper has been accepted.
- [February, 2024]: One <a href=https://cvpr2024.thecvf.com/>CVPR 2024</a> papers have been accepted.
- [Jan, 2024]: 🎉 Our
GPAvatarhas been accepted to ICLR 2024. - [July, 2023]: 🎉 Two ICCV papers have been accepted.
📝 Publications
📩 denotes corresponding author, 📌 denotes co-first author.

Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning
Maomao Li📌, Lijian Lin📌, Yunfei Liu, Ye Zhu, Yu Li
- We propose a novel dual-frame-guided framework for portrait video editing, which propagates fine-grained local modification from the start and end video frames.
- We propose a recursive inference strategy named Quadrant-grid Propagation (QGP), which can stably generate arbitrary-long videos.
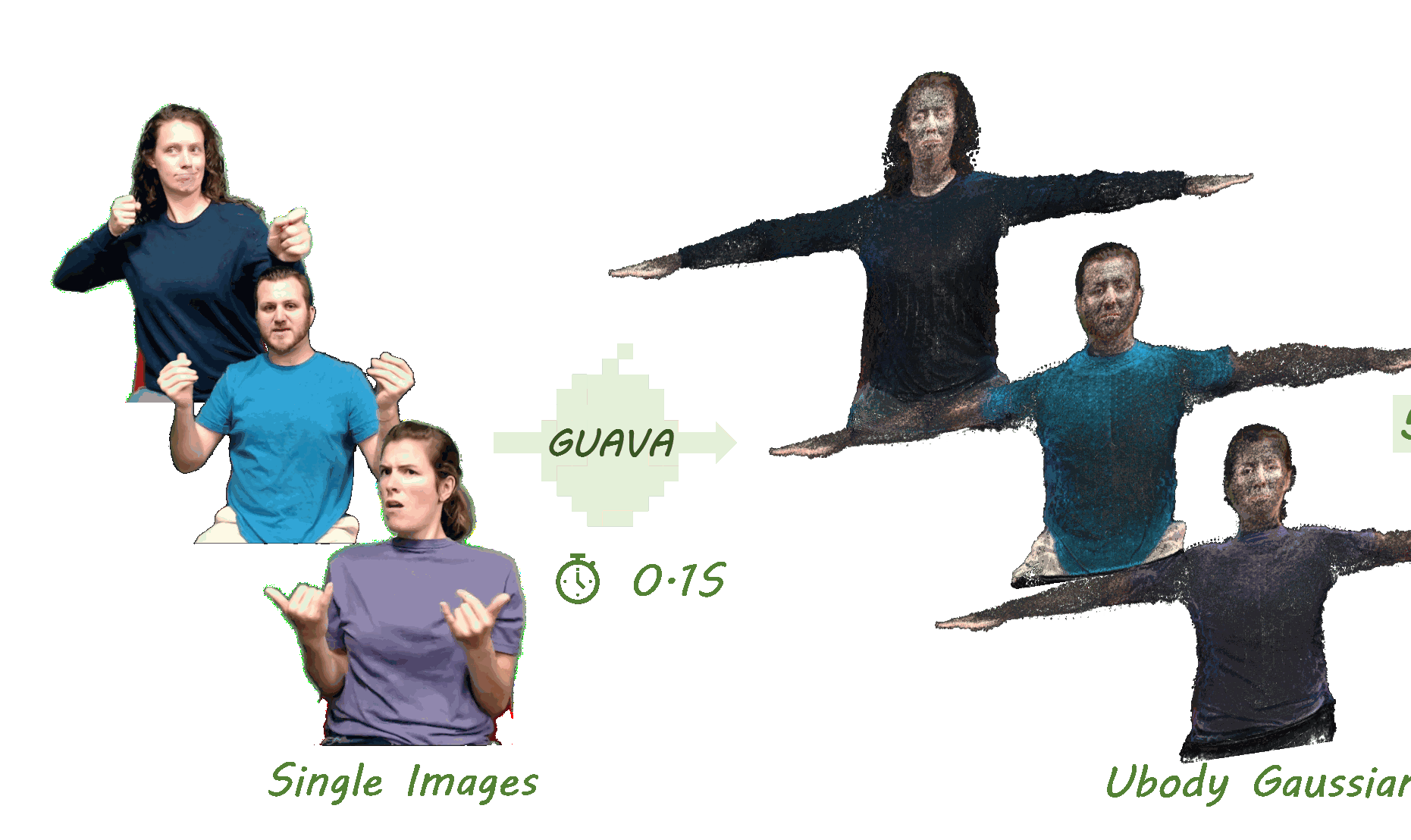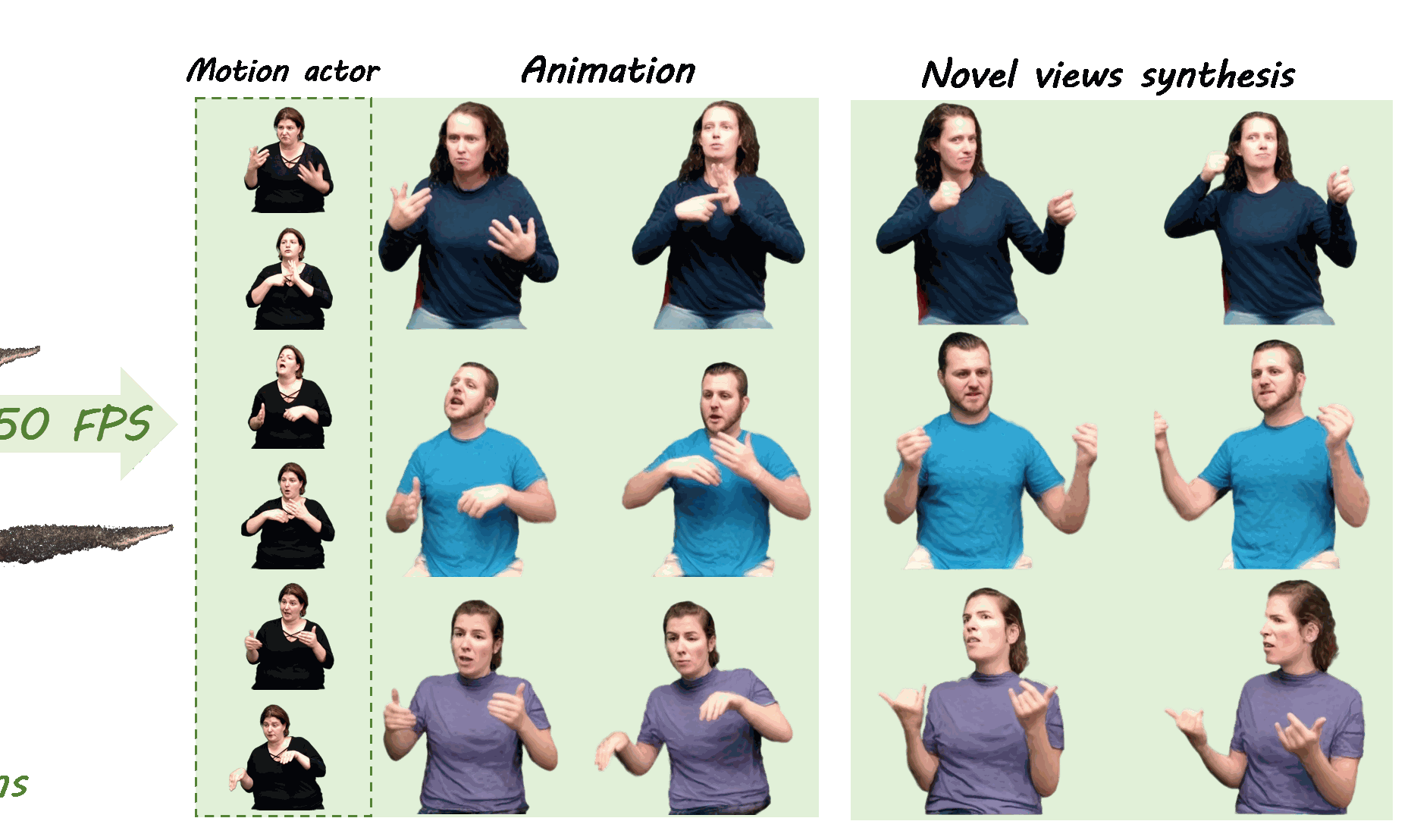
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
Dongbin Zhang, Yunfei Liu📩, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, Haoqian Wang📩
- ⚡️ Reconstructs 3D upper-body Gaussian avatars from single image in 0.1s
- ⏱️ Supports real-time expressive animation and novel view synthesis at 50FPS !
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Kangjie Chen, Minghan Qin, Yu Li, Haoqian Wang
- We propose HRAvatar, a 3D Gaussian Splatting-based method that reconstructs high-fidelity, relightable 3D head avatars from monocular videos by jointly optimizing tracking, deformation, and appearance modeling.
- By leveraging learnable blendshapes, physically-based shading, and end-to-end optimization, HRAvatar significantly improves head quality and realism under novel lighting conditions.

TEASER: Token Enhanced Spatial Modeling for Expressions Reconstruction
Yunfei Liu, Lei Zhu, Lijian Lin, Ye Zhu, Ailing Zhang, Yu Li
- A novel approach that achieves more accurate facial expression reconstruction by predicting a hybrid representation of faces from a single image.
- A multi-scale facial appearance tokenizer and a token-guided neural renderer to generate high-fidelity facial images. The extracted token is interpretable and highly disentangled, enabling various downstream applications.
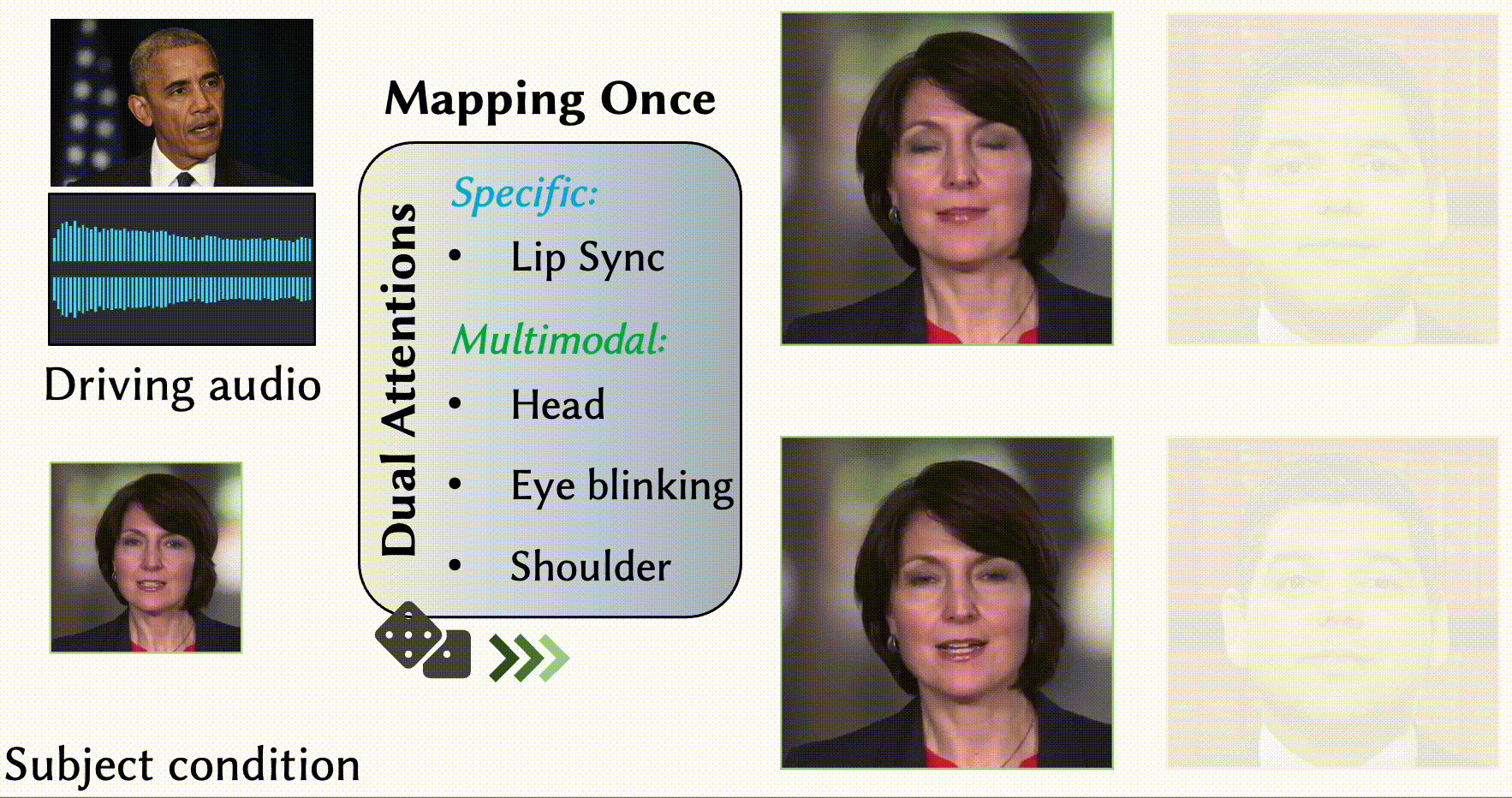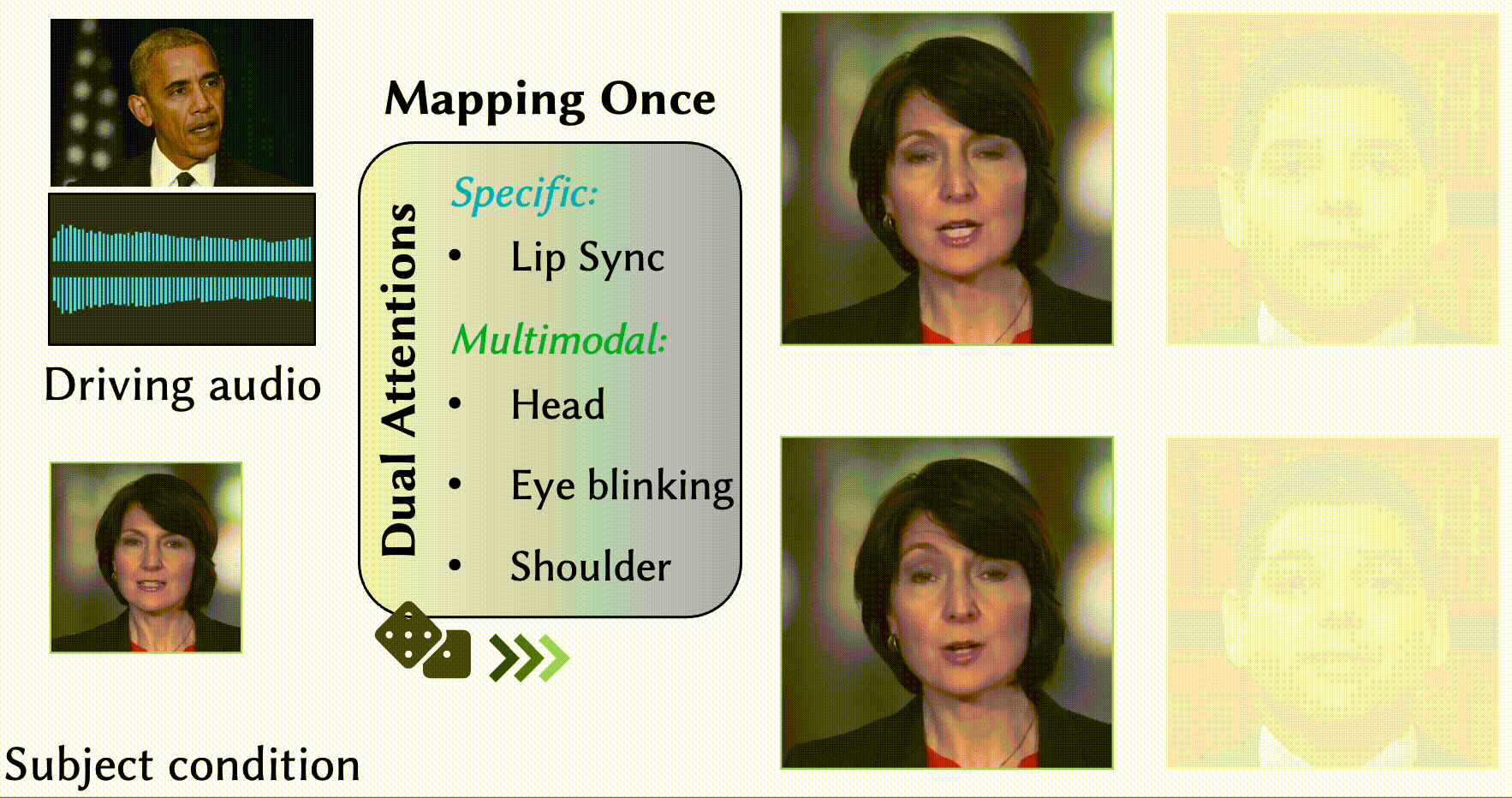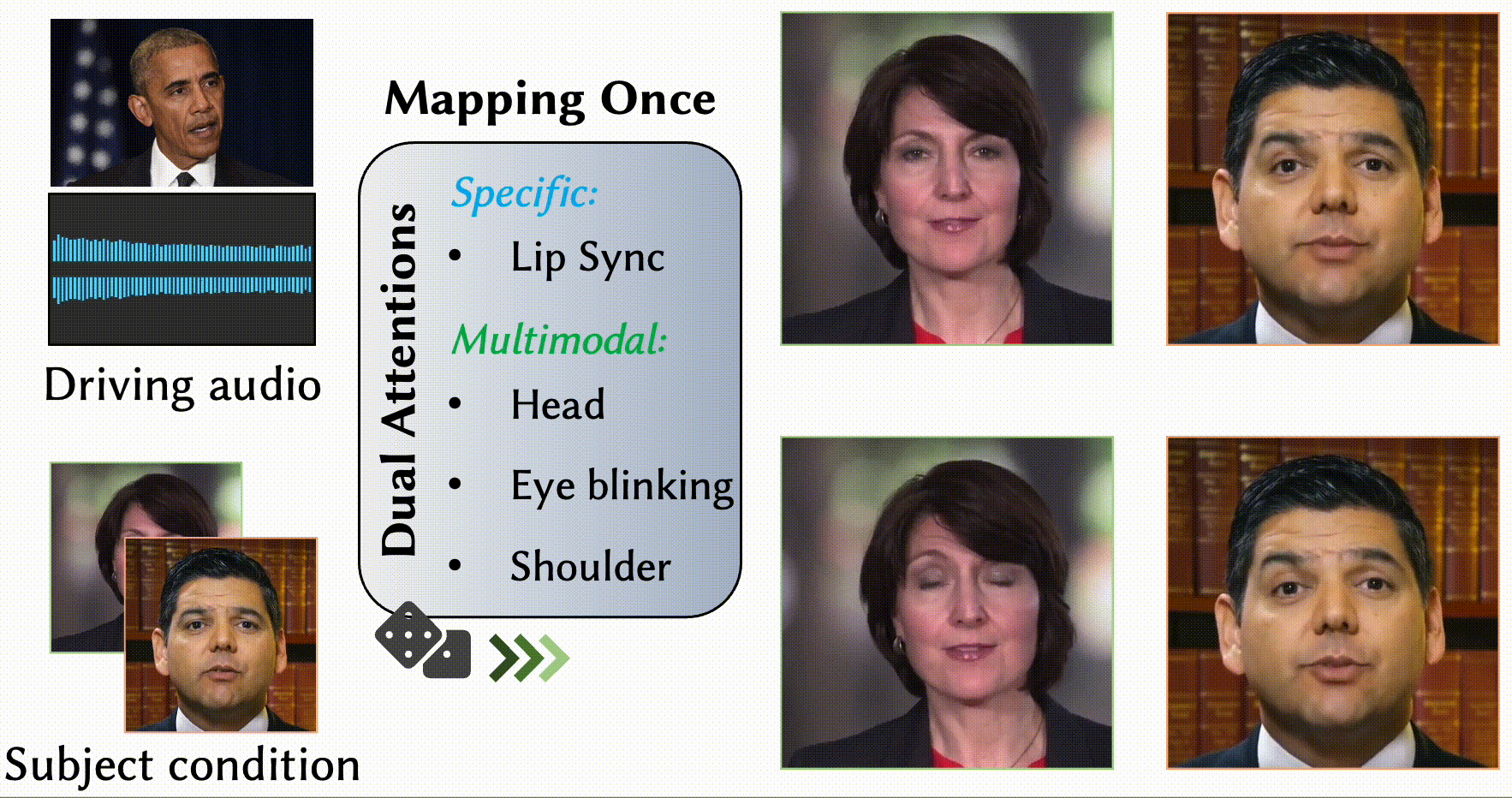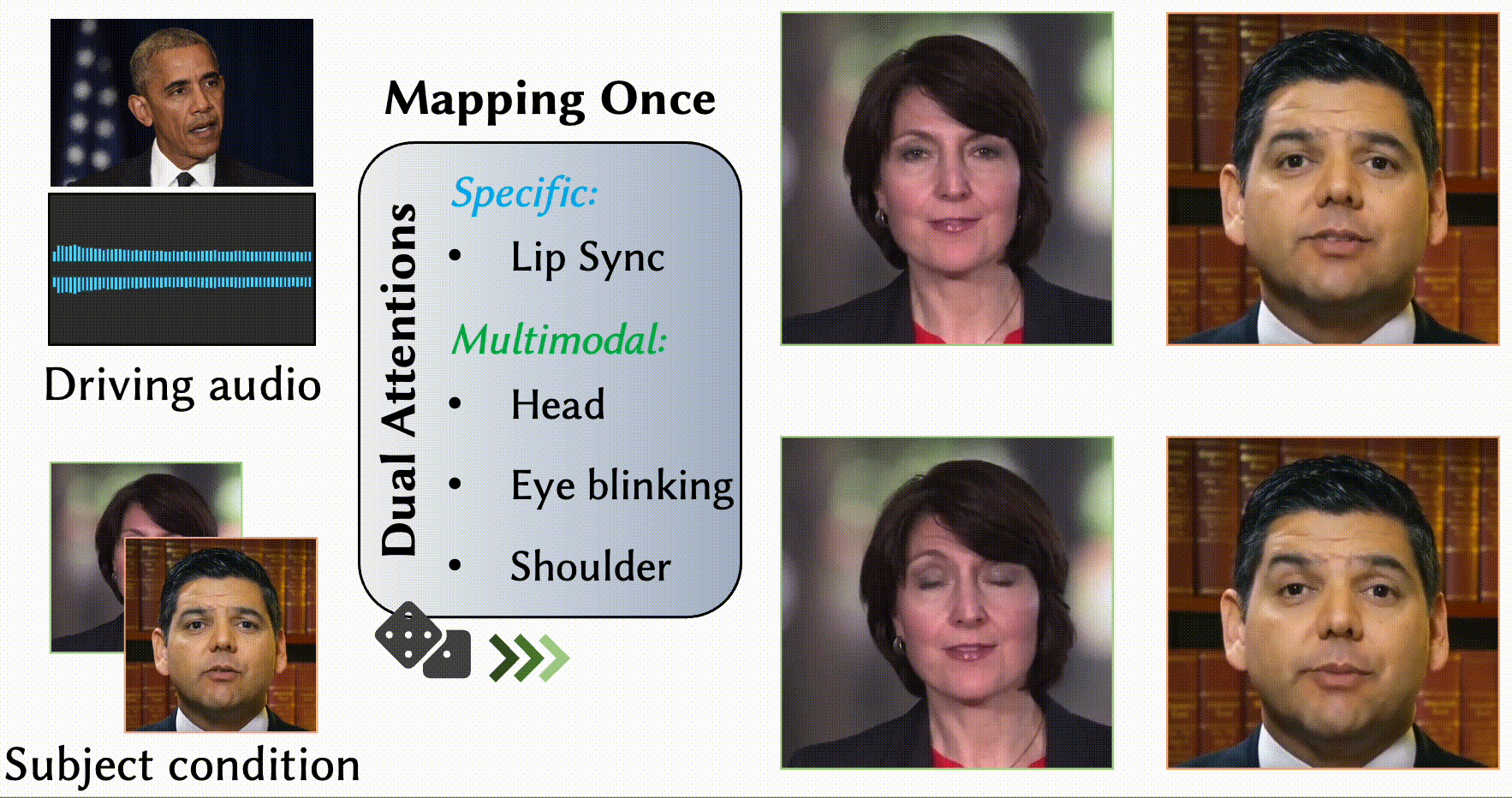
MODA: Mapping-Once Audio-driven Portrait Animation with Dual Attentions
Yunfei Liu, Lijian Lin, Fei Yu, Changyin Zhou, Yu Li
- We propose a unified system for multi-person, diverse, and high-fidelity talking portrait video generation.
- Extensive evaluations demonstrate that the proposed system produces more natural and realistic video portraits compared to previous methods.
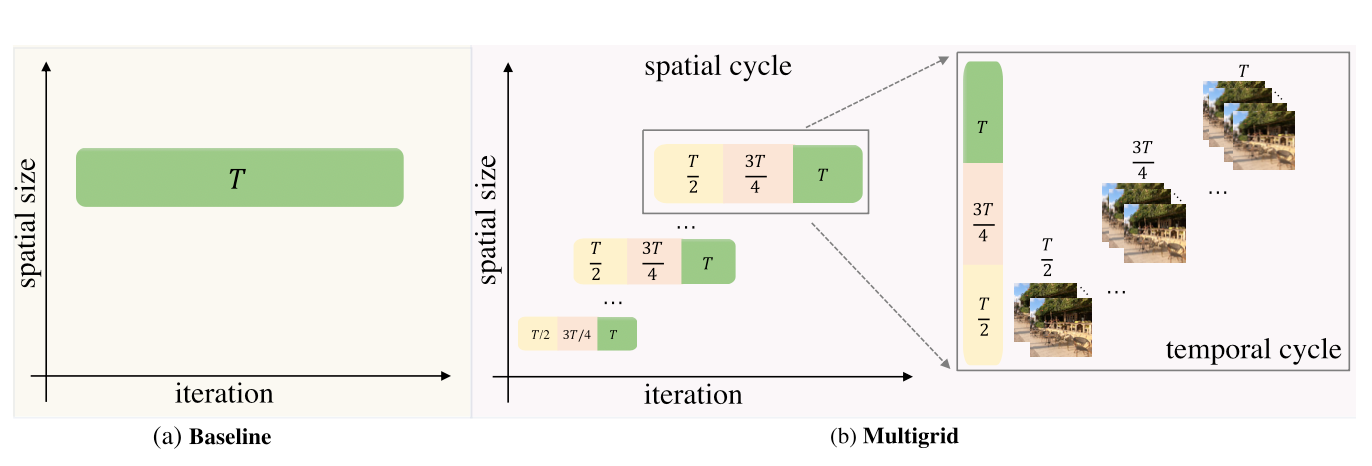
Accelerating the training of video super-resolution models
Lijian Lin, Xintao Wang, Zhongang Qi, Ying Shan
- Our method is capable of largely speeding up training (up to speedup in wall-clock training time) without performance drop for various VSR models.
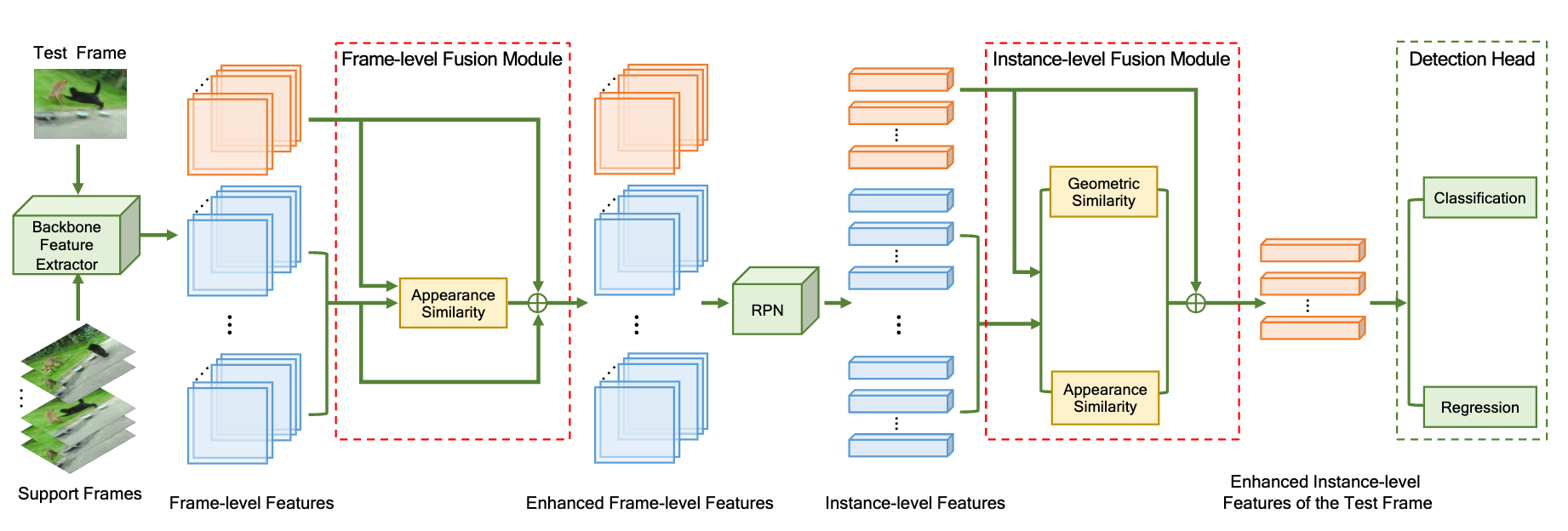
Dual semantic fusion network for video object detection
Lijian Lin📌, Haosheng Chen📌, Honglun Zhang, Jun Liang, Yu Li, Ying Shan, Hanzi Wang
- We present a dual semantic fusion network, which performs a multi-granularity semantic fusion at both frame level and instance level in a unified framework and then generates enhanced features for video object detection.
- We introduce a geometric similarity measure into the proposed dual semantic fusion network along with the widely used appearance similarity measure to alleviate the information distortion caused by noise during the fusion process.
ICCV 2025CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation, Xiangyang Luo, Ye Zhu, Yunfei Liu, Lijian Lin, Cong Wan, Zijian Cai, Shao-Lun Huang, Yu LiAAAI 2025AnyTalk: Multi-modal Driven Multi-domain Talking Head Generation, Yu Wang, Yunfei Liu, Fa-Ting Hong, Meng Cao, Lijian Lin, Yu LiICLR 2024GPAvatar: Generalizable and Precise Head Avatar from Image(s), Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, Tatsuya HaradaICCV 2023Accurate 3D Face Reconstruction with Facial Component Tokens, Tianke Zhang, Xuangeng Chu, Yunfei Liu, Lijian Lin, Zhendong Yang, et al..AAAI 2023Tagging before alignment: Integrating multi-modal tags for video-text retrieval, Yizhen Chen, Jie Wang, Lijian Lin, Zhongang Qi, Jin Ma, Ying Shan
💻 Work Experience
- 2021.07 - 2022.10, Tencent, ARC Lab, Shenzhen, China. Full-time Computer Vision Researcher.
- 2019.012 - 2022.10, Tencent, ARC Lab, Shenzhen, China. Computer Vision Researcher Intern.